|
|
Application Gateway System (AGS)
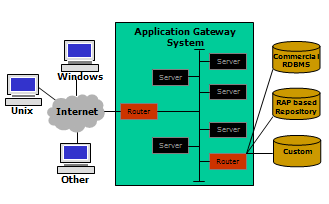
The Application Gateway System (AGS) is a distributed server system consisting of multiple heterogeneous servers that appears as a single high performance system on the Internet. It can provide stand-alone services or access back-end capabilities such as databases or repositories. (See Figure 1)
Clusters of server machines are often used to provide a single logical service on the Internet. This is a cost-effective way to increase response time, throughput and availability of the service. The challenge is to set up the service so that the end-user is transparently connected to one of the servers in the cluster. Some of the commonly used techniques that map the machines in a cluster to the same service name include round robin DNS, packet rewriting, and custom client software. Each technique has its strong and weak points.
As part of a research effort sponsored by the National Science Foundation and the National Library of Medicine, we designed and implemented a new approach based on statistical assignment of processors. The AGS addresses some of the shortcomings of existing solutions by providing a highly scalable and efficient adaptive load balancing mechanism without a central point of failure.
Description of the Rate.d Load Balancing Algorithm
The Application Gateway System (AGS) balances load across a cluster of servers. It uses an adaptive load balancing algorithm that avoids introducing a single point of failure. The algorithm adapts quickly to changes in configuration or actual load of the server machines.
|
Figure 1 - Application Gateway System |
The AGS load balancing algorithm requires some custom client code but is far more flexible than the custom client solution (e.g., in Netscape browsers which special-case the Netscape home page). Compared to round robin DNS, it provides fast, automatic adaptation to changes in load or configuration. Compared to Cisco's LocalDirector, a commercially available packet rewriting device, the fully distributed AGS implementation has no central point of failure and provides more direct measurements of server load.
The Load Balancing Algorithm
The AGS load balancing algorithm works by running a low impact daemon program, known as rate.d, on each server machine in the cluster. Using IP broadcast or multicast, the client sends a single packet containing a request for service to the cluster. The rate.d daemons on all the participating servers receive and evaluate the request. The algorithm selects a single server from the cluster to handle the request, using a proportional share lottery (described below) to balance the load. The selection is made by each daemon independently, but each daemon usually makes the same selection. The selected server sends a unicast response to the client, indicating that it will accept the client's request for service. Once the client receives the response, it initiates the actual service connection to the server machine indicated in the usual way (e.g., by opening an FTP or HTTP connection).
How does a rate.d daemon know that it is the most suitable one to handle a request? The daemon makes job assignments based on load information that is broadcast by each server several times a second. Each daemon monitors these broadcasts and keeps a loosely consistent view of the load on each server. The lottery is weighted so that the number of jobs assigned to a particular server is inversely proportional to its current load.
The lottery is held so that, when the daemons have exactly the same load information, they make the same choice, and when they have approximately the same information, they make the same choice with high probability. The lottery does not depend on any other data, only a hash of the request packet is used to determine the outcome. In particular, the history of previous lotteries held has no effect. This is important to insure that lost client requests do not affect the stability of the algorithm.
In general, the load of a machine varies gradually. We can assume that the load of a machine remains the same until another update is received. This, together with the properties of the lottery, means that losing an occasional broadcast update from another daemon does not greatly affect the lottery outcome. The same is true when updates and requests are received in different orders by different machines. On the other hand, when no updates are received from a particular machine for a longer period of time, that machine is deemed to have crashed and is no longer considered as a candidate.
The rate.d algorithm has a fallback mechanism that takes care of inconsistencies in the lottery outcomes and of lost packets. When more than one machine responds to a request, the client simply uses the first response. When no machine responds to a request, two timeouts come into play.
First, as part of their regular update broadcasts, the rate.d daemons also transmit a list of the request IDs to which they have recently responded, and the other rate.d daemons track this information. When the daemon that should have responded to a particular request fails to indicate this in its update within a certain interval, the other daemons repeat the lottery for this request, this time disregarding the previous lottery winner. If necessary, this process is repeated.
The fallback mechanism takes care of three different sources of inconsistencies between lottery outcomes: differences in relative arrival times between requests and update broadcasts, loss of request packets on some machines, and partial or total loss of update broadcast packets. In rare cases, a second lottery is held and a second response sent unnecessarily; in this case the client will just ignore the second response.
The client can also time out and resubmit its request. The client code must implement a timeout, because the request may be lost on its way to the service cluster. The client timeout period is longer than the lottery's internal timeout because of the higher latency of wide-area communications.
Many other aspects and details of the AGS system can only be mentioned in passing. The update broadcasts contain load information that is calibrated by the capacity of the server, so that load can be balanced across machines with different capacities. The rate.d implementation supports running a number of different services on the same cluster, possibly on different subsets of the machines in the cluster, all handled by a single rate.d daemon per machine. A secure remote management system allows control of system activity, including activation and tuning of rate.d services.